UNIX pipes and output redirects

Pipes and redirects are a core concept of using the command line in any UNIX-like system1. With the new WSL2 package UNIX like concepts are becoming more and more important for developers using Windows as well. Redirecting inputs and outputs is core to how the UNIX system was designed. The rise in popularity of functional programming3 is a great reason to explore this concept again.
This article will help you dig into the concept, and understand why pipes and redirects are so beautiful and versatile. You will be able to take this simple and beautiful design, and apply it to how you design your application’s code.
Commands
When you run an application from your terminal, you are mostly interested in the output of your application. Say you run the ls (or dir on Windows), you expect to see a list of files in the current working directory.
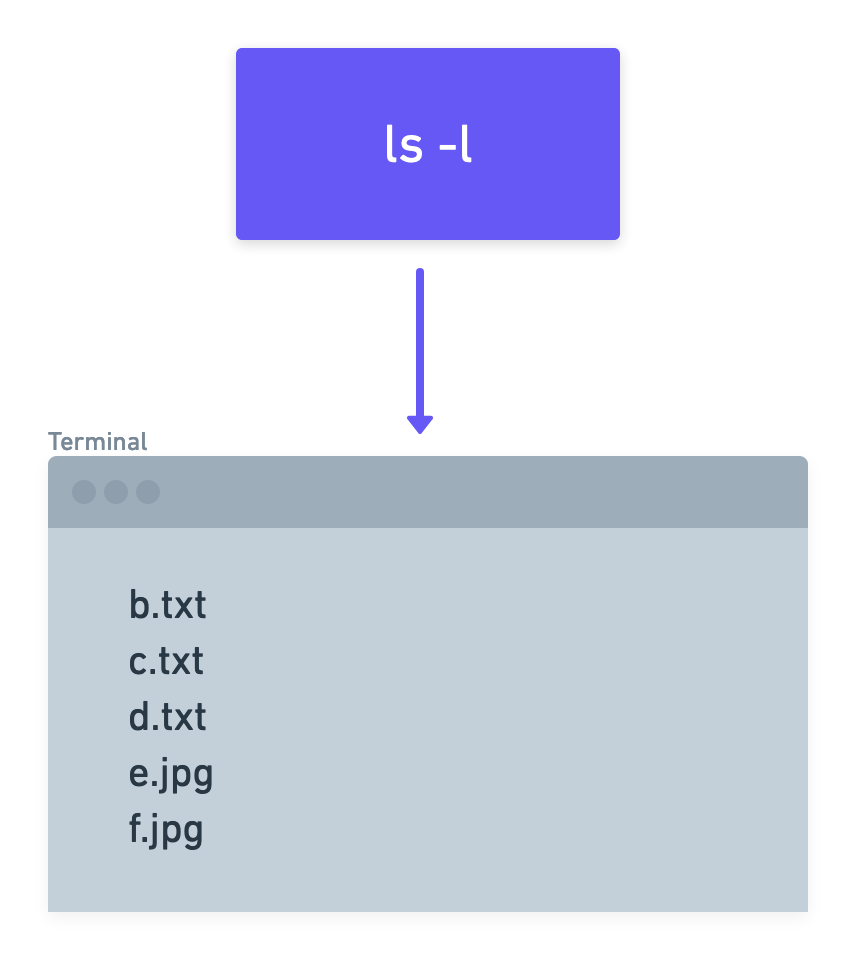
$ ls -l
a.png
b.txt
c.txt
d.txt
e.jpg
f.jpg
There is not much of a concept behind this, it is just the way you would expect things to work.
You could even say, that in this scenario, there are two elements involved: The application ls, which outputs the list of files from a directory, and the terminal4, which receives this output as its input and makes the letters appear on the screen.
Pipes
The concept behind pipes is very simple to grasp: You take two applications, and take the output of the first application, and connect it to the input of the second application. Just like in plumbing you would connect a water source to a faucet with a pipe. The second application, will do its work using the data you put into it’s input, and generate some kind of output. This outpuf of the second application, will be sent to the input of the terminal, which again makes letters appear on the screen.
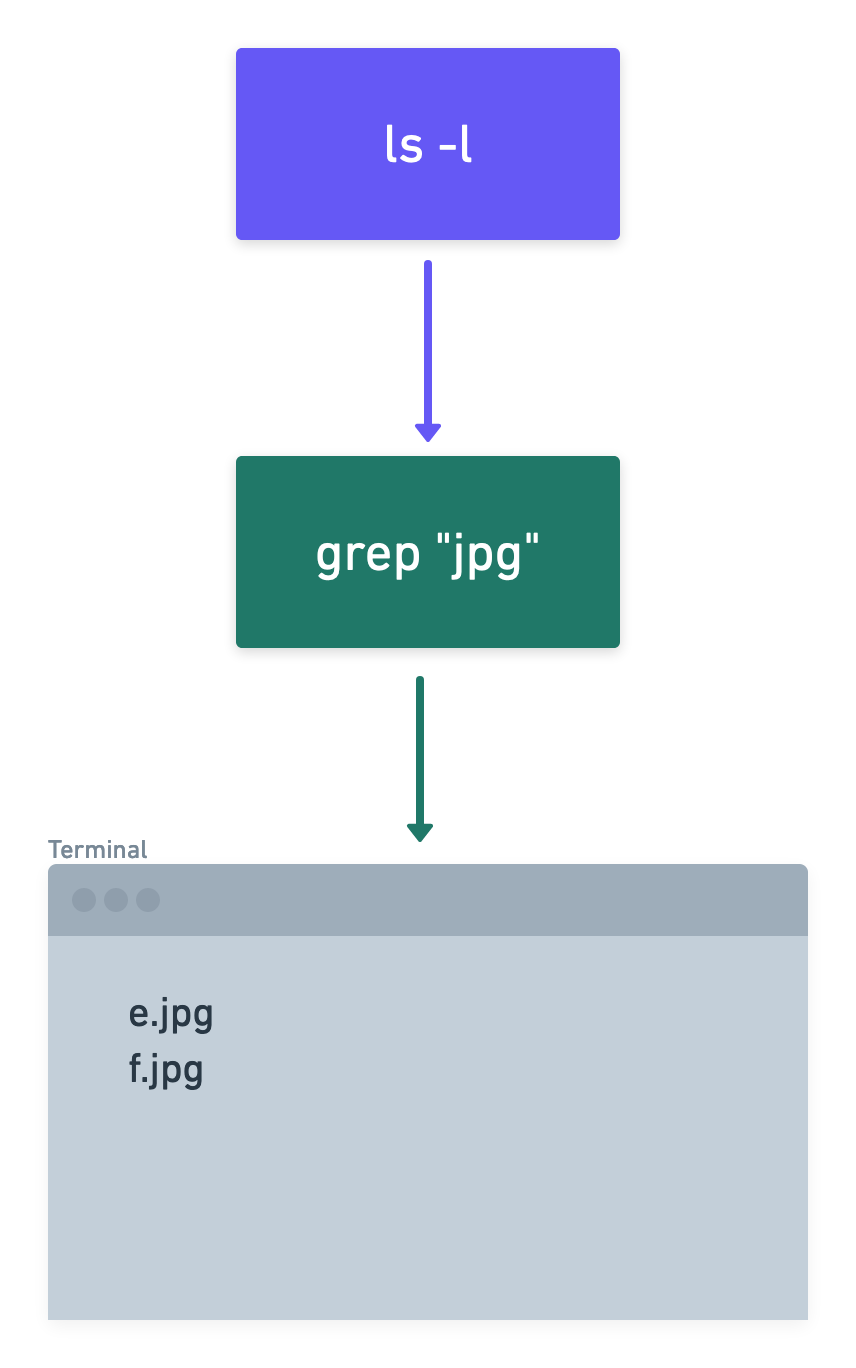
$ ls -l | grep "jpg"
e.jpg
f.jpg
In our little example, the ls -l command will output the list of files in the current directory (see above), and the command grep "jpg" will act as a filter, that only allows lines that have “jpg” in them, to pass through to the terminal. Syntactically this is achieved by putting a little vertical bar | (called pipe character) between the two commands.
You could also understand this setup as a list of commands, chained together. You can chain as many applications in a row as you like: As long as you always have some kind of output, to send to the next command as input, your chain will work perfectly fine.
And this – I think – is the beauty of the UNIX pipes concept: No UNIX system comes with an app, that lets you output the list of jpgs in a current directory. But you can easily make this happen by chaining a command that can output all files to a command that can filter filenames including “jpg”.
There are endless possibilities of what you could achieve with this kind of setup. Every new command you learn does not only give you the power of the specific command, but also allows you to use this command in context of other commands.
Example: Reading logs
Just to give you one example: Let’s say you have a folder full of logs for all your services for the last 7 days. You want to see all the entries from all the files, that were collected at a certain hour of a certain day, and that include a special user id.
First you probably want to output all the logs to see what they look like, using the cat5 command:
cat /var/logs/*.log
2020-04-11 11:43:45 - INFO - Opened connection to service X. - UID 42
2020-04-11 11:43:45 - INFO - Opened connection to service Y. - UID 42
2020-04-11 11:43:47 - INFO - Opened connection to service X. - UID 32
2020-04-11 11:43:55 - ERR - Connection timed out for X. - UID 42
2020-04-12 11:56:32 - INFO - Sending confirmation email - UID 32
2020-04-13 22:56:32 - INFO - Sending confirmation email - UID 32
2020-04-14 09:12:22 - INFO - Sending confirmation email - UID 42
Next, you only want logs from the 11th of April, so let’s filter the output:
cat /var/logs/*.log | grep "2020-04-11"
2020-04-11 11:43:45 - INFO - Opened connection to service X. - UID 42
2020-04-11 11:43:45 - INFO - Opened connection to service Y. - UID 42
2020-04-11 11:43:47 - INFO - Opened connection to service X. - UID 32
2020-04-11 11:43:55 - ERR - Connection timed out for X. - UID 42
Last, let’s make sure to only output the rows for the user id 42:
cat /var/logs/*.log | grep "2020-04-11" | grep "UID 42"
2020-04-11 11:43:45 - INFO - Opened connection to service X. - UID 42
2020-04-11 11:43:45 - INFO - Opened connection to service Y. - UID 42
2020-04-11 11:43:55 - ERR - Connection timed out for X. - UID 42
Even though the command cat /var/logs/*.log | grep "2020-04-11" | grep "UID 42" might look intimidating at first, it is actually quite simple. If you build up your command chain step by step, you have full control over what is happening and can build up the complexity of this command chain one step at a time.
Pipes and filters
Understanding this concept is super helpful in doing almost anything with a UNIX like command line: You don’t need to build specialized applications, that can do very specific things. You actually want the opposite: You want to make applications, that are very simple and versatile, so that they can be connected to other applications that are the same. This is the fundamental idea behind UNIX pipes.
And this simple and beautiful concept can (and probably should) be applied to all kinds of challenges, that we try to solve with code: If you need to do a lot of data processing using a Jupyter notebook6, you are basically doing the same thing: You build up your data cleaning and filtering pipeline, one step at a time.
If you are building sophisticated Javascript applications, in a “functional” way, you also follow this principle (or at least you should ;)
db.getUsers()
.filter(user => user.age < 18)
.map(user => { user.lda = false; return user; })
.map(user => db.updateUser(user));
This design principle allows you to design beautiful and well structured applications, and at least in my opinion, it is a great way to think about the problem you are trying to solve.
Redirects
Files are so special, that people usually want to have a way to deal with them in a very convenient way. This is why UNIX has two special “signs”, which allow to either write to a file, or append to a file.
Let’s say you want to write the output of some command you write to put into a file. I will use our logging example from above:
cat /var/logs/*.log | grep "2020-04-11" | grep "UID 42" > output.txt
The > output.txt at the end of the line will tell the system to write the generated output from the last command in the chain to a file called “output.txt”. If this file does not exist, it will just create a file and put the content in their. Notice, that running this line, will no longer give you any output in your terminal, because you redirected the output into a file.
This “sign” also has a sibling, which will keep the current content of the mentioned file, and just append the new output at the end. >> will append, instead of replace the content of that file.
cat /var/logs/*.log | grep "2020-04-11" | grep "UID 42" >> output.txt
Just like the previous command, our new example ending in >> output.txt will show no output on the terminal, as the output is – again – redirected away from the terminal, into your file.
Recap
So to wrap this up: One of the core UNIX principles is to connect the output of one simple and versatile application to the input of another simple and versatile application. As a result, it is very simple, to build complex functionality right from your terminal, by just “chaining” applications together.
You can find this principle in many parts of software development, from number crunching to developing sophisticated functional software.
I hope this little article helped you understand this core UNIX principle. As always, I am happy to hear about your thoughts and opinions.
-
This includes all UNIXes like openBSD or MacOSX and Linux distributions. ↩
-
WSL is short for Windows Subsystem for Linux. It is a recent (as of 2020) addition to the Windows operating system and is still under development (Version 2 was just released). It basically is a stripped down version of Linux, running alongside Windows, allowing you to run most Linux applications, especially command line applications. This is a great help for developers, who are using Windows to develop in an environment that makes heavy use of the Linux or UNIX ecosystem. ↩
-
Functional programming is a concept that is very old, but became popular again in recent years. It is very hard to boil it down into a footnote, but the basic concept is that you try to write your application as a series of functions, that follow a strict ruleset, which ensures that these functions do not create any side effects: They are supposed to receive input and return output based on that. If I call a function with the input “X” today, it should yield the exact same result as it will tomorrow or in two years. There are many benefits for this, and I recommend digging deeper into this starting at the Wikipedia article about functional programming. ↩
-
Terminal is a term commonly used for an application that allows you to control a computer via text input. There is a lot of history behind it, which is why this term is not 100% correct in many use cases, but it is the term most commonly used. The well-known desktop and server operating systems (Linux, Windows, MacOSX) all come with some kind of Terminal. Mobile operating systems often offer some kind of app to allow you to at least connect to another computer’s system via text input. ↩
-
catis a very simple unix command, which allows to output the content of one or more files. If you don’t pipe its output into another command, it will just output a file’s content onto the terminal. ↩ -
Jupyter notebooks are a system that is heavily used by data scientists and analysts all over the world, to do data analysis. It will allow you to write Python code that loads and processes data and prints graphs. The beauty of it is its nice and simple graphical user interface and portability. ↩
This website does not use any tracking or feedback mechanism. Instead, I would love for you to get in touch with me to let me know if you liked it or if you have any suggestions or questions.